spark sql을 사용하여 json의 복잡한 유형을 파싱하고 다루는 방법을 알아보자
spark sql support module pyspark.sql.fuctions
from pyspark.sql.functions import *
from pyspark.sql.types import *
중첩된 열에 대해 "." 을 사용해서 가지고 올 때
schema 먼저 선언
1. using a Struct
schema = StructType().add("a", StructType().add("main", IntegerType()))
2. using a map
schema = StructType().add("a", MapType(StringType(), IntegerType()))
중첩된 열에 대해 "*" 를 사용해서 b 필드를 가져올 때
events = jsonToDataFrame("""
{
"a": {
"b": 1
}
}
""", schema)
display(events.select("a.b"))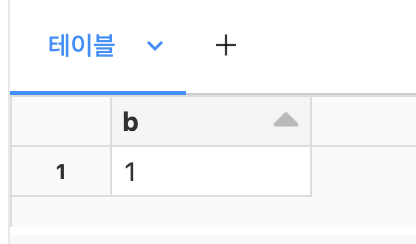
중첩된 열에 대해 "*" 를 사용해서 하위 필드를 다 가져올 때
events = jsonToDataFrame("""
{
"a": {
"b": 1,
"c": 2
}
}
""")
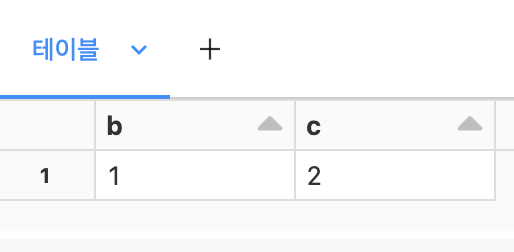
display(events.select("a.*"))
explode를 사용하여 각 요소들을 각 행으로 가져올 때
events = jsonToDataFrame("""
{
"a": [1, 2]
}
""")
display(events.select(explode("a").alias("x")))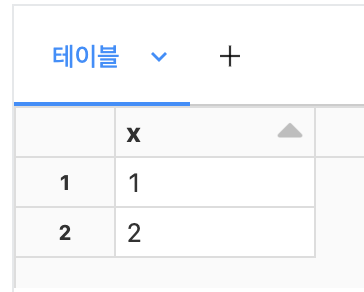
기타사항
중첩된 열에 대해서 중첩된 열의 name과 같이 쓰고 싶은 경우
{"event":"event1","prop":{"device_id":"device123","login_time":"2023-12-20T08:00:00","os_version":"Android 10","app_version":"1.2.0","network_type":"4G"}}
event, prop_device_id, prop_login_time, prop_os_version, prop_app_version, prop_network_type 형식으로 나왔으면 함
이부분은 추가 Test 예정
반응형





