Northwind.mdb를 databricks와 jdbc로 연결
jdbc:ucanaccess는 Microsoft Access 데이터베이스에 jdbc 를 통해 연결하기 위한 URL 스키마 중 하나
- ucanaccess.jar , 외 2개 총 4개의 jar 다운로드 후 클러스터 라이브러리에 설치
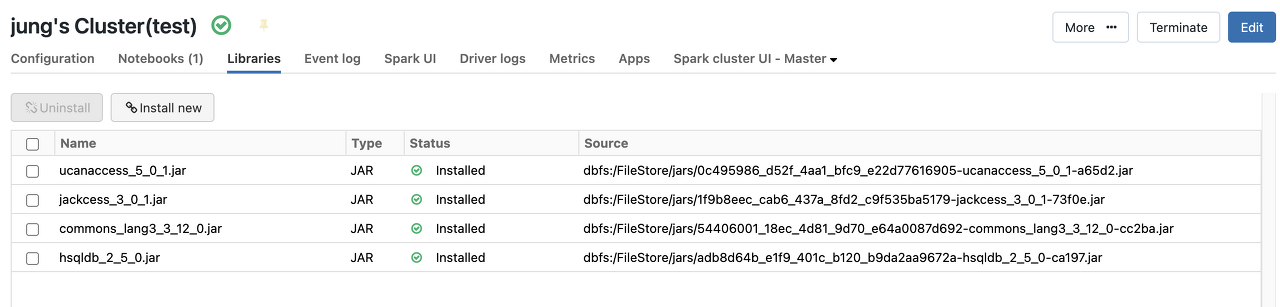
- mdb를 dbfs에 수동 load한다 [mdb는 별도로 user, password 정보 필요없음]
import org.apache.spark.sql.jdbc.{JdbcDialect, JdbcDialects} case object MSAccessJdbcDialect extends JdbcDialect { override def canHandle(url: String): Boolean = url.startsWith("jdbc:ucanaccess") override def quoteIdentifier(colName: String): String = s"[$colName]" } JdbcDialects.registerDialect(MSAccessJdbcDialect)
// 위의 코드는 UCanAccess JDBC 드라이버를 Spark SQL에서 사용할 수 있도록 등록하는 코드입니다. 코드를 실행하면 Spark SQL에서 UCanAccess JDBC 드라이버를 사용할 수 있습니다.
데이터브릭스에서 ODBC 드라이버를 직접 사용하는 것은 지원되지 않습니다. 그러나 ODBC 드라이버를 사용하는 대신 해당 드라이버와 연결되는 JDBC 드라이버를 사용할 수 있습니다. 예를 들어, MS Access 데이터베이스에 대한 ODBC 드라이버를 사용할 수 없으므로, UCanAccess JDBC 드라이버를 사용하여 해당 데이터베이스에 연결할 수 있습니다.
3. url/ driver 설정
# JDBC URL 설정 url = "jdbc:ucanaccess:///dbfs/FileStore/yourname/Northwind.mdb"
# JDBC 드라이버 클래스명 설정 jdbc_driver_class = "net.ucanaccess.jdbc.UcanaccessDriver"
4. 파이썬으로 작성한 jdbc코드
from pyspark.sql import SparkSession
table_list = ["Suppliers", "Customers", "Employees", "Products", "Shippers", "Orders", "Order Details", "Categories"]
url = "jdbc:ucanaccess:///dbfs/FileStore/yourname/Northwind.mdb"
spark = SparkSession.builder.appName("JDBC to Spark DataFrame").getOrCreate()
for table_name in table_list:
save_table_name = table_name.replace(" ", "_")
df = spark.read.format("jdbc") \
.option("driver", jdbc_driver_class) \
.option("url", url) \
.option("dbtable", f"[{table_name}]").load()
df.write.mode("overwrite").saveAsTable(f"yourname_jdbc.{save_table_name}")- Windows odbc 연결 코드 (참고)
# 앨리언코드 <Mac에서는 Microsoft Access를 지원하지 않기 때문에, Microsoft Access를 사용하여 MDB 파일을 열 수는 없습니다> windows는 가능할듯 import pandas as pd import pyodbc # 파일 경로 지정 mdb_file = r'/Users/yourname/Downloads/Northwind.mdb' driver = '{Microsoft Access Driver (*.mdb, *.accdb)}' #드라이버 설치 해야함 마이크로소프트 엔진에서 cnxn = pyodbc.connect(f'Driver={driver};DBQ={mdb_file}') crsr = cnxn.cursor() # 테이블 읽기 및 데이터 저장 table_list=[] for table_name in crsr.tables(tableType='TABLE'): table_list.append(table_name.table_name) for table in table_list: dfTable = pd.read_sql(f"SELECT * FROM [{table}]".format(table), cnxn) # print(f"{table}.csv".replace(" ","").format(table)) dfTable.to_csv(f"{table}.csv".replace(" ","").format(table),header=True)
How to use ucanaccess (ms access jdbc driver) in azure data bricks?
I am using azure data bricks and am trying to read .mdb files in as part of an ETL program. After doing some research, the only jdbc connector that i've found for ms access (.mdb) formats is "ucana...
stackoverflow.com
반응형