카프카란?
각 DB와 시스템 사이에 kafka를 도입하여 보내는 쪽(producer)과 받는 쪽 (consumer) 신경 쓸 필요 없이
kafka에서 중개역할 수행
- controller
- 각 broker에게 담당 파티션 할당 수행
- broker 동작 모니터링 관리
- kafka broker (=server)
- 실행된 Kafka application server를 의미함
- producerdprp message를 받아서 offset 할당
- apache zookeeper (=message 관리자)
- 여러 대의 broker를 중재하고 연결하는 역할
- 데이터 연계 시 broker에게 데이터를 전달하는 코디네이터 역할을 수행함
- broker의 메타 데이터 저장 및 공유
데이터를 주고받기 위해 사용되는 Java library
- kakfa client
실제 데이터 통신이 필요할 때, 원하는 db와 시스템을 end to end 방식으로 연계하는 것이 아닌 kafka cluster를 두고 kafka application 간에 통신을 하는것

EC2 instance
- ubuntu - 22.04 LTS (HVM), SSD volume type | t2.medium | EBS 8Gib
- 바탕화면에 pem key 놓고, cmd 열어서 ec2 연결
mv jenny-pem.pem /Users/yourdesktop/Desktop
ssh -i "jenny-pem.pem" ubuntu@13.125.197.148java install
$ sudo apt-get update
$ sudo apt-get install openjdk-8-jdk
$ java -versionkafka install
wget https://archive.apache.org/dist/kafka/2.5.0/kafka_2.12-2.5.0.tgz
#wget 설치
tar xvf kafka_2.12-2.5.0.tgz
#tar 아카이브 압축 해제https://velog.io/@jwpark06/AWS-EC2에-Kafka-설치하기
Zookeeper 실행
/home/ubuntu/kafka_2.12-2.5.0/bin/zookeeper-server-start.sh -daemon \
/home/ubuntu/kafka_2.12-2.5.0/config/zookeeper.properties
jps
# 주키퍼 프로세스 확인kafka 실행
/home/ubuntu/kafka_2.12-2.5.0/bin/kafka-server-start.sh -daemon \
/home/ubuntu/kafka_2.12-2.5.0/config/server.properties
jps
# kafka 프로세스 확인Topic 생성
./kafka-topics.sh --create --bootstrap-server <ip>:9092 \
--replication-factor 1 --partitions 3 --topic testproducer / consumer 실행
#producer
./kafka-console-producer.sh --bootstrap-server <ip>:9092 --topic test
# command + T
#consumer
./kafka-console-consumer.sh \
--bootstrap-server <ip>:9092 --topic test --from-beginningPipeline databricks
from pyspark.sql.functions import *
from pyspark.sql.types import *
# 스트리밍 데이터 소스 설정
df = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "3.34.186.209:9092") \
.option("subscribe", "test") \
.option("startingOffsets", "earliest") \
.option("failOnDataLoss", "false") \
.option("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer") \
.load()
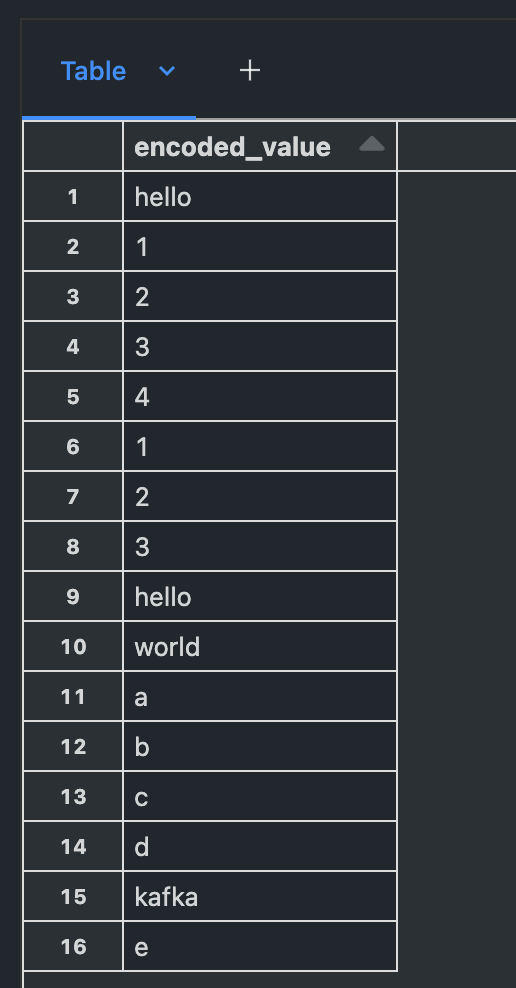
#value 컬럼 UTF-8로 인코딩
encodedDF = df.select(decode(col("value"), "UTF-8").alias("encoded_value"))
# 출력
display(encodedDF)Data 확인
🔥 참고 🔥
알아두면 유용한 맥 터미널 명령어 모음 | 요즘IT
알아두면 유용한 맥 터미널 명령어 모음 | 요즘IT
터미널이란 컴퓨터와 사용자 간 소통을 위한 인터페이스입니다. 코딩을 접해보지 않은 분들이라도 개발자들이 검정 화면에 코드는 아닌데 뭔가 입력하는 것을 본 적이 있으실 수도 있는데요,
yozm.wishket.com
반응형